

Per practicar amb l’aplicació AntConc, he triat el blog feminista El dit a la nafra, que es subtitula “Contra les violències masclistes”.
He seleccionat les últimes 6 entrades, publicades entre el 8 de desembre de 2016 i l’1 de maig de 2017. He obviat dues entrades que contenien textos en castellà, i he convertit els textos en un fitxer .txt; finalment, he seleccionat l’opció de no diferenciar entre majúscules i minúscules, perquè considero que per al tipus d’anàlisi que haig de fer no té cap utilitat distingir noms propis.
La llista de paraules que queda té 6083 tokens ordenats de major a menor freqüència, i 1647 types. Després, he aplicat la llista de mots buits en català que va publicar en Lluís de Yzaguirre a la pàgina del Laboratori de Tecnologies Lingüístiques de la UPF [http://latel.upf.edu/morgana/altres/pub/ca_stop.htm]. Al repetir el càlcul de freqüència, el nombre de tokens i types ha disminuït substancialment a 2314 i 1405 respectivament.
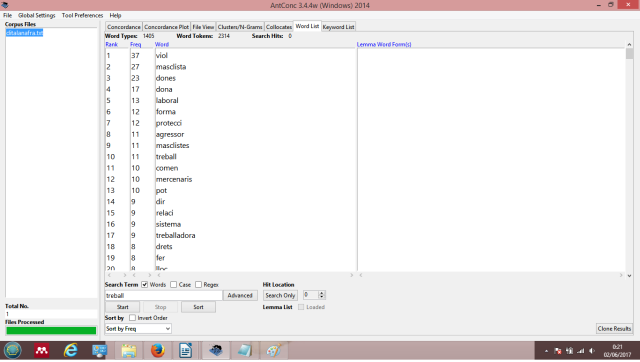
Les paraules més freqüents ja ens indiquen de què va la cosa: violència, masclista, dones, dona, protecció, agressor, masclistes, treball, treballadora, drets …
Si ordenem la llista per final de mot, observem que els participis conjugats en femení (escoltada, inadaptada, deshumanitzada…) són a les posicions més altes de freqüència (17-34), i els conjugats en masculí (format, confiat, denunciat) són a les més baixes (1147-1216). Però cal tenir en compte que s’hi barregen altres paraules acabades en -ada o -at (vegada, jornada, edat, patriarcat).
A continuació, he lematitzat el corpus. Això significa relacionar totes les flexions d’una paraula: singular amb plural, formes verbals, masculí amb femení. Aquesta darrera opció, però, no l’he aplicat perquè, atesa la temàtica del blog, relacionar en un mateix lema treballador i treballadora, per exemple, confondria els resultats. Per preparar adequadament la llista, he partit de la llista alfabètica de mots, que permet detectar de seguida les paraules del mateix lema.
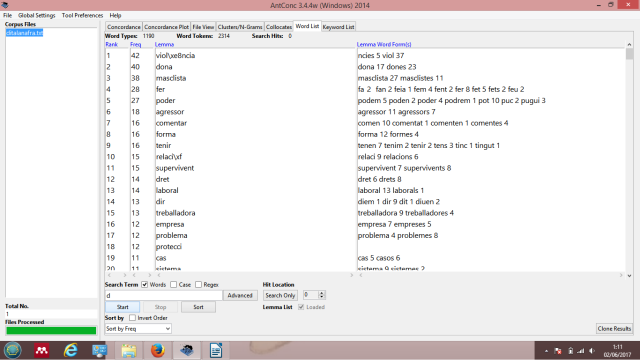
Després d’aplicar la lematització, tenim els mateixos tokens però molts menys types (han passat a 1190); és a dir, tenim els mateixos mots, però més agrupats. Com a conseqüència, ha canviat l’ordre de les paraules segons la freqüència: dona ha sumat dones, i ha passat al segon lloc; supervivent + supervivents han pujat al lloc 15; els verbs també han arribat als primers llocs, gràcies a què han incorporat les diverses formes verbals, i el verb fer, per exemple, ha pujat del lloc 19 al 4.
Si apliquem la fòrmula type-token ration, segons la qual com més s’acosti a 1 el resultat de dividir el nombre de types pel nombre de tokens, major riquesa lèxica, trobem que El dit a la nafra té una riquesa lèxica mitjana, de 0’51. Entenc que, en un blog de naturalesa combativa com aquest, es busca més l’efectivitat comunicativa que la qualitat literària, i que les persones que hi escriuen ho fan de manera voluntària i amateur.
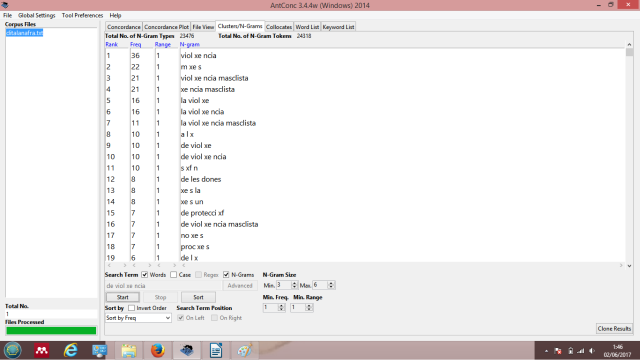
Amb l’opció clusters podem observar la freqüència d’agrupacions de paraules. Com que en aquesta opció el programa no aplica les stopwords, convé seleccionar n-grames de 3 mots com a mínim. En aquesta modalitat es fa evident el problema de reconeixement dels caràcters; tot i que hem aplicat la codificació Unicode (UTF-8) que recomana el manual, l’aplicació ha dividit els mots accentuats, o bé ha substituït els accents per un conjunt de caràcters; així, el mot violència és transformat en viol\xE8ncia i en alguns casos apareix fraccionat com a viol\xE, viol xe, etc. Com que la lematització tampoc no opera en els clusters, no he trobat la manera de resoldre-ho. De tota manera, el cluster demostra que les entrades d’aquest blog són coherents amb el seu crit de guerra “Contra les violències masclistes”, perquè [violència masclista] és el grup de paraules més freqüent, si obviem viol xe ncia i m xe x (més), que apareixen als primers llocs, i que no s’han d’interpretar com a agrupacions de mots.
Si cerquem les concordances d’aquests primers mots, es confirma que la violència masclista és al cim de la llista. Aquest és el resultat de la paraula número 1:
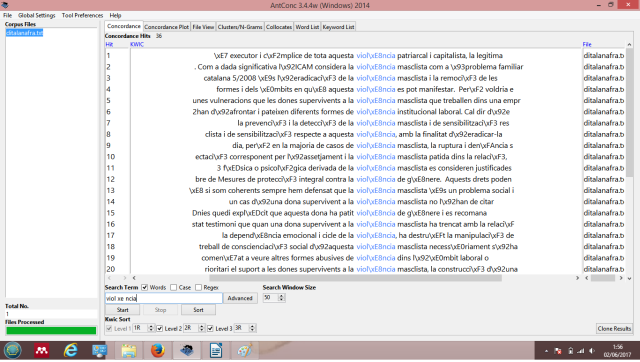
Pel que fa a la segona paraula, el lema dona, la trobem associada als conceptes supervivent (en la majoria dels casos), treballadora i, a més distància, violència masclista, denúncia, ajudar, revictimitzada i silenci. Tots ells transmeten la gravetat de les conseqüències de la violència contra la qual treballa el blog.
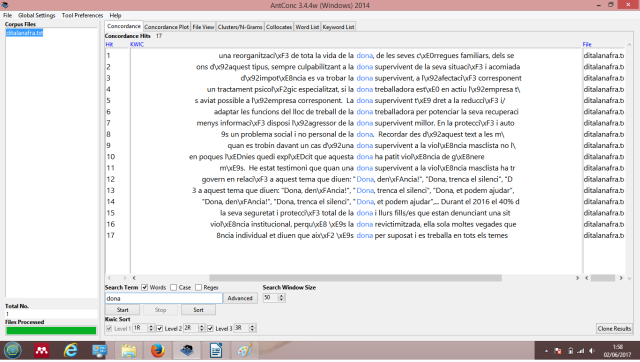
La concordança del tercer mot, violència, l’aparella majoritàriament amb masclista, com hem vist més amunt, però també apareixen els conceptes agressor, problema familiar, sensibilització, ruptura, denúncia, amenaça, xarxa solidària, patriarcat, delictes sexuals, vexació, violència sexual. Aquest conjunt defineix l’abast del problema i algunes vies possibles de solució, que deixen clar el caràcter de denúncia i de lluita del blog.
♦♦ La imatge destacada pertany a AntConc

